
Ruby 코드 성능 최적화 (feat. ruby-prof, Benchmark)
초기 스타트업은 기능에 비해 성능이 덜 중요시 되는 개발을 하게 됩니다. 사용자가 적을 땐 성능을 신경쓰는 것 보다 아이템을 빨리 검증하기 위한 기능 개발이 더 중요하기 때문인데요, 드라마앤컴퍼니도 처음엔 기능 위주의 개발을 하다 사용자가 늘어남에 따라 자연스럽게 성능도 중요시 하여 개발하고 있습니다. 드라마앤컴퍼니의 대부분 Web/API 프로젝트들은 Ruby와 Ruby on Rails로 만들어졌습니다. Ruby는 느리다고 자주 까이는 언어인데요, 이번 글에서는 내가 만든 프로그램이 느린 이유가 정말 Ruby라는 언어 때문인지, 코드의 다른 부분에 문제가 있는 것인지 근거를 가지고 판단하고 어떻게 성능 개선을 할 수 있을지 그 방법을 다뤄보고자 합니다. 이 글에서 예시로 든 언어가 Ruby지만 Tool만 다를뿐 이 글에서 소개하는 성능 최적화 방법은 모든 언어에 걸쳐 비슷하다고 생각합니다. 또 이 글에서는 성능을 “속도”로 가정하고 다루고 있지만, 상황에 따라 정확도 등 다양한 기준이 될 수 있음을 염두해주셨으면 합니다. 크게 3단계로 나뉘어 설명해보자 합니다. Tools에서는 Ruby 성능 최적화에 많이 사용되는 툴들인 Benchmark(성능 측정), ruby-prof(프로파일러)를 소개합니다. 성능 최적화 과정에서는 필요한 과정들을 설명하며 실제 사례에서는 제가 실제로 성능 최적화를 진행하며 정리했던 문서를 예시로 다뤄봅니다.
Tools
Benchmark
Ruby에서 기본적으로 제공하고 있는 Benchmark 모듈입니다. 단순하여 사용하기 매우 간단하지만 많은 쓸모가 있습니다. 아래와 같은 코드를 작성하면 report 메소드에 넘기는 코드 블럭를 수행하는데 든 소요 시간을 측정해줍니다. 결과의 real부분이 실제 코드를 수행하는데 사용한 총 시간을 초 단위로 나타냅니다.
require 'benchmark'
Benchmark.bm do |x|
x.report('느린') do
1_000_000.times.map do |i|
i.to_s
end
end
x.report('빠른') do
Array.new(1_000_000) do |i|
i.to_s
end
end
end
user system total real
느린 0.210000 0.010000 0.220000 ( 0.218153)
빠른 0.190000 0.000000 0.190000 ( 0.187891)
ruby-prof
아마 Ruby에서 가장 많이 사용되는 프로파일러입니다. 원하는 코드 블럭들에 대해서 리포트를 측정할 수 있으며 결과를 다양한 포맷으로 제공합니다. gem을 설치한 뒤 다음과 같은 코드만 작성하면 해당 코드 블럭에 대한 프로파일링을 기록할 수 있습니다.
gem install ruby-prof
require 'ruby-prof'
result = RubyProf.profile do
dummy_list.each do |dummy|
foo(dummy)
end
end
# Text로 된 그래프 형식으로 출력
File.open "remember-profile-graph.html", 'w' do |file|
RubyProf::GraphHtmlPrinter.new(result).print(file)
end
# Call Stack을 html 형식으로 출력
File.open "remember-profile-stack.html", 'w' do |file|
RubyProf::CallStackPrinter.new(result).print(file)
end
측정한 report를 다양한 포맷으로 제공하는 printer들이 많은데 그 중 제가 가장 많이 쓰는 printer들은 GraphPrinter와 CallStackPrinter입니다. 두 printer들에 대한 예시와 결과를 읽을 법에 대해서 간단히 설명해드리겠습니다.
GraphPrinter
측정한 코드 블럭에서 호출되었던 모든 메소드들을 모아서, 각 메소드들이 얼만큼의 시간을 소요했으며 어떤 메소드들에 의해 호출되고 어떤 메소드들을 호출했는지 보여줍니다. 텍스트로만 되어있기 때문에, 빠르게 어떤 부분들이 가장 시간을 많이 잡아먹고 몇 번 호출되는지 파악하기 용이합니다. 다음은 GraphPrinter로 출력한 예시입니다.
Measure Mode: wall_time
Thread ID: 70310439543100
Fiber ID: 70310456289620
Total Time: 0.05264616012573242
Sort by: total_time
%total %self total self wait child calls name
--------------------------------------------------------------------------------
100.00% 0.01% 0.053 0.000 0.000 0.053 1 PrintersTest#setup
0.053 0.000 0.000 0.053 1/1 Object#run_primes
--------------------------------------------------------------------------------
0.053 0.000 0.000 0.053 1/1 PrintersTest#setup
99.99% 0.01% 0.053 0.000 0.000 0.053 1 Object#run_primes
0.052 0.000 0.000 0.052 1/1 Object#find_primes
0.001 0.000 0.000 0.001 1/1 Object#make_random_array
0.000 0.000 0.000 0.000 1/1 Object#find_largest
--------------------------------------------------------------------------------
0.052 0.000 0.000 0.052 1/1 Object#run_primes
98.35% 0.00% 0.052 0.000 0.000 0.052 1 Object#find_primes
0.052 0.000 0.000 0.051 1/1 Array#select
--------------------------------------------------------------------------------
0.052 0.000 0.000 0.051 1/1 Object#find_primes
98.34% 0.61% 0.052 0.000 0.000 0.051 1 Array#select
0.051 0.000 0.000 0.051 1000/1000 Object#is_prime
--------------------------------------------------------------------------------
0.051 0.000 0.000 0.051 1000/1000 Array#select
97.74% 0.93% 0.051 0.000 0.000 0.051 1000 Object#is_prime
0.051 0.051 0.000 0.000 1000/1001 Integer#upto
--------------------------------------------------------------------------------
0.000 0.000 0.000 0.000 1/1001 Object#find_largest
0.051 0.051 0.000 0.000 1000/1001 Object#is_prime
96.91% 96.91% 0.051 0.051 0.000 0.000 1001 Integer#upto
--------------------------------------------------------------------------------
0.001 0.000 0.000 0.001 1/1 Object#run_primes
1.51% 0.00% 0.001 0.000 0.000 0.001 1 Object#make_random_array
0.001 0.000 0.000 0.000 1/1 Array#each_index
0.000 0.000 0.000 0.000 1/1 Class#new
--------------------------------------------------------------------------------
0.001 0.000 0.000 0.000 1/1 Object#make_random_array
1.50% 0.56% 0.001 0.000 0.000 0.000 1 Array#each_index
0.000 0.000 0.000 0.000 1000/1000 Kernel#rand
--------------------------------------------------------------------------------
0.000 0.000 0.000 0.000 1000/1000 Array#each_index
0.94% 0.72% 0.000 0.000 0.000 0.000 1000 Kernel#rand
0.000 0.000 0.000 0.000 1000/1000 Kernel#respond_to_missing?
--------------------------------------------------------------------------------
0.000 0.000 0.000 0.000 1000/1000 Kernel#rand
0.22% 0.22% 0.000 0.000 0.000 0.000 1000 Kernel#respond_to_missing?
--------------------------------------------------------------------------------
0.000 0.000 0.000 0.000 1/1 Object#run_primes
0.12% 0.02% 0.000 0.000 0.000 0.000 1 Object#find_largest
0.000 0.000 0.000 0.000 1/1001 Integer#upto
0.000 0.000 0.000 0.000 1/1 Array#first
--------------------------------------------------------------------------------
0.000 0.000 0.000 0.000 1/1 Object#make_random_array
0.01% 0.00% 0.000 0.000 0.000 0.000 1 Class#new
0.000 0.000 0.000 0.000 1/1 Array#initialize
--------------------------------------------------------------------------------
0.000 0.000 0.000 0.000 1/1 Class#new
0.01% 0.01% 0.000 0.000 0.000 0.000 1 Array#initialize
--------------------------------------------------------------------------------
0.000 0.000 0.000 0.000 1/1 Object#find_largest
0.00% 0.00% 0.000 0.000 0.000 0.000 1 Array#first
결과는 - - - 로 나뉘어진 여러 블록으로 이루어져 있습니다.
다음은 결과 표를 읽을 때 중요하게 보셔야 할 항목들입니다.
name | 가장 중요한 부분입니다. 27번째 줄과 같이 %total, %self 값이 존재하는 줄의 name이 해당 블럭이 나타내는 메소드입니다. 그 블록은 해당 메소드를 설명하고 있다고 보시면 됩니다. 26-28번째 줄은 Object#is_prime 메소드를 나타내고 있습니다. |
%self | 전체 코드 블럭을 수행한 시간 중, 이 메소드 자체(자식 호출 제외)가 소요한 시간 비중을 나타냅니다. 이 값이 큰 메소드일수록 우리가 찾고있는 병목 메소드일 확률이 높습니다. |
self | %self와 비슷하지만 전체 시간과 상대적 비율이 아닌 이 메소드를 수행하는데 절대적으로 몇 초를 소요했는지 나타냅니다. |
calls | 이 메소드가 몇 번 호출되었는지를 나타냅니다. 해당 블럭에서 바로 부모가 호출한 횟수/전체 블럭에서 이 메소드가 호출된 총 횟수입니다. Integer#upto 메소드는 총 1,001회 호출되었는데, Object#is_prime 메소드에 의해 1,000번 (27번째 줄) Object#find_largest 메소드에 의해 1번 (52번째 줄)호출된 것을 알 수 있습니다. |
CallStackPrinter
전체 call stack을 html 형식으로 보여줍니다. 필요한 상황에 따라 node를 접고, 일정 값 이상의 %를 소요한 메소드들만 필터링하여 볼 수 있습니다. 각 node를 보면 A%(B%)와 같은 형식으로 표시되는데, 앞의 A는 위 GraphPrinter의 %self에 해당하는 값이고, B는 부모의가 호출한 자식 메소드들을 기준으로 소요한 시간의 비율입니다.
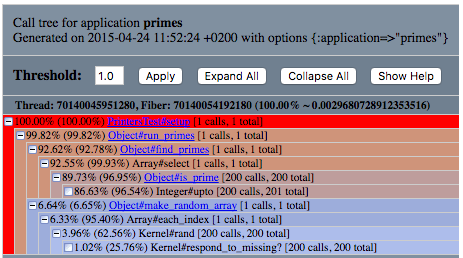 CallStackPrinter 예시
CallStackPrinter 예시성능 최적화 과정
성능 최적화는 다음 6단계들로 이루어집니다. 매우 당연한 이야기일지라도 한단계라도 대충 했다간 잘못된 방향을 잡아 이 모든 과정이 결국 의미없는 시간낭비가 되어버릴 수 있습니다. 귀찮더라도 매 단계를 확실히 하고 가야 우리가 원하는 답을 찾을 수 있습니다.
1. 문제 정의
정확히 어떤 문제가 있는지, 왜 성능을 측정하고 최적화를 시도하려는지 정의합니다.
2. 단계 정의
문제가 되는 부분이 어떤 과정을 거쳐 동작하는지 하나 하나 명확하게 정의합니다. 이 정의가 명확해야 변수들을 제거할 수 있으며 올바른 성능 측정 방향을 세울 수 있습니다.
3. 성능 측정
문제라고 생각하는 코드의 성능을 측정합니다. 우선 성능 저해의 원인이라고 의심되어 변경해볼 변수(조작변인)을 남겨두고 나머지는 이 성능 측정에 영향을 주지 않은 상수(통제변인)를 확실히 나눠야 합니다. DB, 네트워크 상태와 같은 외부적인 요인부터 테스트에 사용하는 변수 등 내부적인 요인 등 모두 테스트 결과에 영향을 미치지 않도록 통제변인으로 만들어야 합니다. 물론 이런 요인들을 100% 완벽한 상수로 만들 수는 없기 때문에 최대한 영향도를 줄이기 위하여 충분히 많은 횟수를 반복해야 합니다. 이 과정을 조금이라도 어설프게 정의했다간, 뒤의 테스트들을 비교할 대상이 없어져 의미없는 시간 낭비가 되어버립니다. 조작변인과 통제변인을 정의하고 실험 환경을 준비했다면 같은 코드를 여러번 실행하고 각각 어느정도의 시간이 소요되었는지 기록합니다.
4. 분석
코드를 분석합니다. ruby-prof와 같은 프로파일링 툴을 이용하여 코드를 세세히 분석하고 어떤 메소드가 병목이 되고 있는지 감이 아닌 타당한 근거를 갖고 판단합니다.
5. 개선
병목이 되고있는 부분과 이유를 찾아냈으면 병목을 해결하여 더 좋은 성능을 낼 수 있도록 코드를 개선합니다.
6. 성능 비교
개선된 코드의 성능과 원래 코드의 성능을 비교해보고 어느정도의 성능이 향상되었는지 측정합니다. 만약 만족하지 못한 결과가 나왔을 경우에는 다시 분석 단계로 돌아갑니다.
실제 사례
앞서 말씀드린 Tool과, 최적화 과정은 드라마앤컴퍼니에서 실제로 자주 사용하고 있습니다. 이론보다는 실제 사용 사례가 좋을 것 같아 적당한 예를 사내 wiki에서 하나 가져왔습니다. 이는 제가 리멤버의 ‘연락처 지인찾기’ 기능의 성능을 개선하며 실제로 정리했던 내용입니다. 간단하게 풀린 문제로 이 글의 예시로 좋을 것 같습니다. Wiki의 내용을 거의 그대로 복사하느라 문체가 다른 점 이해부탁드립니다 :)
문제 정의
- ‘연락처 지인찾기’ API에 연락처가 많은 (몇 천건) 회원이 요청할 경우 각 응답을 처리하는데 너무 늦어져 서버의 request queue가 다 차버리는 현상이 발생함.
- ‘연락처 지인찾기’란 사용자 주소록의 휴대폰 번호 목록을 이용하여 리멤버 회원들 중 같은 전화번호를 사용하는 회원들을 찾는 과정이다.
단계 정의
연락처 지인 찾기 기능은 다음 단계들로 진행된다.
- 클라이언트에서 사용자 휴대폰 주소록의 전화번호 목록을 일정 단위로 잘라서 API 서버로 여러번 업로드
- 클라이언트에서 넘긴 raw 전화번호를 파싱
- 휴대전화번호 목록을 가지고 DB에서 같은 지역번호를 갖고 있는 리멤버 회원들을 찾음
- DB에서 조회한 회원들 중 국가번호와 지역번호가 모두 같은 회원들을 찾음
- 일치하는 회원들의 목록을 반환
성능 측정
Ruby에서 기본적으로 Benchmark 모듈을 이용하여 성능을 측정하고 ruby-prof를 이용하여 성능을 분석한다. 검색 대상 사용자의 수와 전화번호-사용자 매칭률을 두 변수로 정의하고 성능을 측정하며 비교한다. 사용자 수는5, 10, 20, 30, 50, 100, 150, 500에 대하여 진행하고 매칭률은 100%, 50%, 10%로 나누어 측정한다. Profiling은 150 user, 50%의 매칭률에 대해서만 진행한다. 측정하는 코드는 다음과 같다.
require 'benchmark'
class Test
class << self
def ready
@users = Zeus::User::Entity.where.not(national_phone: '').limit(1_000).load
end
def run
run_single 5, 1
run_single 5, 0.5
run_single 5, 0.1
run_single 10, 1
run_single 10, 0.5
run_single 10, 0.1
run_single 20, 1
run_single 20, 0.5
run_single 20, 0.1
run_single 30, 1
run_single 30, 0.5
run_single 30, 0.1
run_single 50, 1
run_single 50, 0.5
run_single 50, 0.1
run_single 100, 1
run_single 100, 0.5
run_single 100, 0.1
run_single 150, 1
run_single 150, 0.5
run_single 150, 0.1
run_single 500, 1
run_single 500, 0.5
run_single 500, 0.1
run_single 1_000, 1
run_single 1_000, 0.5
run_single 1_000, 0.1
nil
end
def run_single(size, hit_rate = 1)
users = @users.sample size
phones = users.map do |u|
if u.national_phone.present?
Contact::PhoneNumber.new(u.national_phone)
end
end.compact
# 전화번호 가지고 있는 비율
phones = phones.sample(phones.size * hit_rate)
Benchmark.bm do |x|
x.report("User size: #{size}, Hit rate: #{hit_rate}") do
users = users.select do |user|
phones.any? { |phone| user.mobile == phone }
end
end
end
end
def run_prof
users = @users.sample 150
phones = users.map do |u|
if u.national_phone.present?
Contact::PhoneNumber.new(u.national_phone)
end
end.compact
# 전화번호 가지고 있는 비율
phones = phones.sample(phones.size * 0.5)
result = RubyProf.profile do
users = users.select do |user|
phones.any? { |phone| user.mobile == phone }
end
end
# print a graph profile to text
File.open "#{Rails.root}/tmp/bulk-upload-profile-graph.html", 'w' do |file|
RubyProf::GraphHtmlPrinter.new(result).print(file)
end
File.open "#{Rails.root}/tmp/bulk-upload-profile-stack.html", 'w' do |file|
RubyProf::CallStackPrinter.new(result).print(file)
end
end
end
end
Test.ready
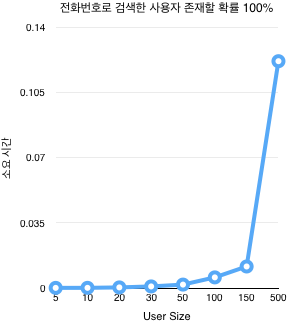
기존 성능
다음은 기존 코드로 성능 테스트를 진행한 결과이다.
User size | Hit rate | user | system | total | real time |
5 | 1 | 0.040000 | 0.000000 | 0.040000 | 0.034104 |
5 | 0.5 | 0.020000 | 0.000000 | 0.020000 | 0.018707 |
5 | 0.1 | 0.000000 | 0.000000 | 0.000000 | 0.000003 |
10 | 1 | 0.130000 | 0.00000 | 0.130000 | 0.129068 |
10 | 0.5 | 0.090000 | 0.00000 | 0.090000 | 0.094217 |
10 | 0.1 | 0.020000 | 0.00000 | 0.020000 | 0.021157 |
20 | 1 | 0.510000 | 0.00000 | 0.510000 | 0.513110 |
20 | 0.5 | 0.360000 | 0.00000 | 0.360000 | 0.356309 |
20 | 0.1 | 0.080000 | 0.00000 | 0.080000 | 0.086764 |
30 | 1 | 1.070000 | 0.01000 | 1.080000 | 1.072212 |
30 | 0.5 | 0.800000 | 0.00000 | 0.800000 | 0.807687 |
30 | 0.1 | 0.190000 | 0.00000 | 0.190000 | 0.199311 |
50 | 1 | 2.900000 | 0.01000 | 2.910000 | 2.907888 |
50 | 0.5 | 2.130000 | 0.00000 | 2.130000 | 2.136653 |
50 | 0.1 | 0.550000 | 0.00000 | 0.550000 | 0.546068 |
100 | 1 | 11.780000 | 0.030000 | 11.810000 | 11.838261 |
100 | 0.5 | 8.570000 | 0.020000 | 8.590000 | 8.626450 |
100 | 0.1 | 2.150000 | 0.010000 | 2.160000 | 2.157522 |
150 | 1 | 26.100000 | 0.060000 | 26.160000 | 26.241357 |
150 | 0.5 | 19.310000 | 0.050000 | 19.360000 | 19.406512 |
150 | 0.1 | 4.880000 | 0.010000 | 4.890000 | 4.908961 |
500 | 1 | 291.680000 | 1.000000 | 292.680000 | 294.109574 |
500 | 0.5 | 220.220000 | 0.890000 | 221.110000 | 222.306764 |
500 | 0.1 | 56.030000 | 0.220000 | 56.250000 | 56.555782 |
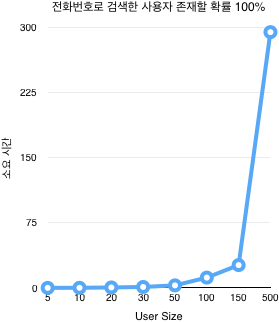 ](https://blog.dramancompany.com/wp-content/uploads/2016/11/image2016-11-8-14-35-54.png)
](https://blog.dramancompany.com/wp-content/uploads/2016/11/image2016-11-8-14-35-54.png) 

 [
[ 테스트 결과를 보면 전화번호로 검색된 리멤버 사용자 수와 거의 비례하게 소요 시간이 증가하며, 현재 사용하고 있는 사용자 수가 그리 많지 않음에도 매우 오랜 시간이 걸린다.
테스트 결과를 보면 전화번호로 검색된 리멤버 사용자 수와 거의 비례하게 소요 시간이 증가하며, 현재 사용하고 있는 사용자 수가 그리 많지 않음에도 매우 오랜 시간이 걸린다.
분석
ruby-prof로 상세하게 call-stack 등 어느 메소드에서 많은 시간을 소요했는지 분석해보면 다음과 같다.
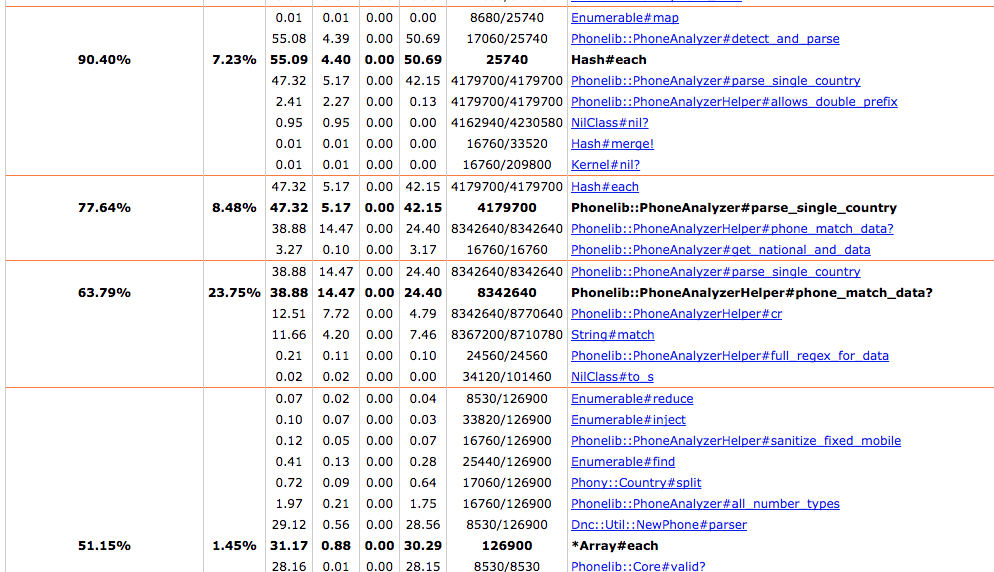 ](https://blog.dramancompany.com/wp-content/uploads/2016/11/image2016-11-8-15-36-4.png)[
](https://blog.dramancompany.com/wp-content/uploads/2016/11/image2016-11-8-15-36-4.png)[
가장 많은 시간을 소요한 부분은 전화번호 파싱을 담당하는 gem인 Phonelib의 Phonelib::Core#parse 부분임을 알 수 있다. API에서는 Phonelib을 이용한 파싱을 2번 사용하고 있다.
- 클라이언트에서 넘겨준 raw한 전화번호를 파싱하여 국가코드/지역번호로 나누기 위해서
- 사용자 연락처를 가져오기 위하여 user.mobile 메소드를 호출하여 사용자 번호를 PhoneNumber 클래스로 파싱할 때
1번 경우는 올바른 비교를 위하여 필수적이지만, 2번 경우는 이미 테이블에 국가코드/지역번호로 나뉘어져 저장되어있기 때문에 다시 Phonelib을 이용해 파싱하는 과정은 불필요한 과정이다. 따라서 해당 부분을 제거하여 성능을 개선해본다.
개선
개선하여 변경한 코드는 다음과 같다.
# 기존
phones.any? { |phone| user.mobile == phone }
# 개선
phones.any? { |phone| user.international_code == phone.international_code && user.national_phone == phone.national_number }
User::Entity에서 mobile을 불러 Phonelib를 호출 하는 부분을 제거하고 바로 값을 비교하도록 수정했다. 그로 인하여 변경된 테스트 코드는 다음과 같다.
# 위와 같음..
def run_single(size, hit_rate = 1)
users = @users.sample size
phones = users.map do |u|
if u.national_phone.present?
Contact::PhoneNumber.new(u.national_phone)
end
end.compact
# 전화번호 가지고 있는 비율
phones = phones.sample(phones.size * hit_rate)
Benchmark.bm do |x|
x.report("User size: #{size}, Hit rate: #{hit_rate}") do
users = users.select do |user|
# phones.any? { |phone| user.mobile == phone }
phones.any? { |phone| user.international_code == phone.international_code && user.national_phone == phone.national_number }
end
end
end
end
# 위와 같음..
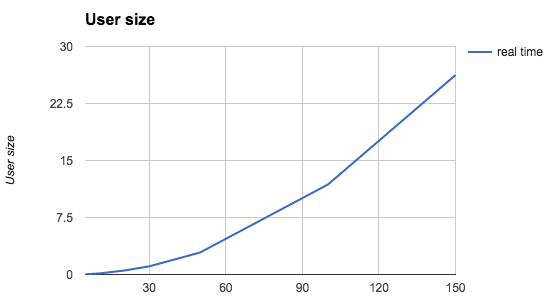
그리고 개선 후 성능 측정 결과는 다음과 같다.
User size | Hit rate | user | system | total | real time |
5 | 1 | 0.000000 | 0.000000 | 0.000000 | 0.000177 |
5 | 0.5 | 0.000000 | 0.000000 | 0.000000 | 0.000147 |
5 | 0.1 | 0.000000 | 0.000000 | 0.000000 | 0.000003 |
10 | 1 | 0.000000 | 0.000000 | 0.000000 | 0.000197 |
10 | 0.5 | 0.000000 | 0.000000 | 0.000000 | 0.000228 |
10 | 0.1 | 0.000000 | 0.000000 | 0.000000 | 0.000170 |
20 | 1 | 0.000000 | 0.000000 | 0.000000 | 0.000426 |
20 | 0.5 | 0.000000 | 0.000000 | 0.000000 | 0.000432 |
20 | 0.1 | 0.000000 | 0.000000 | 0.000000 | 0.000316 |
30 | 1 | 0.000000 | 0.000000 | 0.000000 | 0.000952 |
30 | 0.5 | 0.000000 | 0.000000 | 0.000000 | 0.000856 |
30 | 0.1 | 0.000000 | 0.000000 | 0.000000 | 0.000484 |
50 | 1 | 0.000000 | 0.000000 | 0.000000 | 0.001935 |
50 | 0.5 | 0.000000 | 0.000000 | 0.000000 | 0.001270 |
50 | 0.1 | 0.000000 | 0.000000 | 0.000000 | 0.000728 |
100 | 1 | 0.010000 | 0.000000 | 0.010000 | 0.005805 |
100 | 0.5 | 0.010000 | 0.000000 | 0.010000 | 0.004177 |
100 | 0.1 | 0.000000 | 0.000000 | 0.000000 | 0.001609 |
150 | 1 | 0.010000 | 0.000000 | 0.010000 | 0.011655 |
150 | 0.5 | 0.000000 | 0.000000 | 0.000000 | 0.008360 |
150 | 0.1 | 0.010000 | 0.000000 | 0.010000 | 0.002741 |
500 | 1 | 0.120000 | 0.000000 | 0.120000 | 0.121817 |
500 | 0.5 | 0.090000 | 0.000000 | 0.090000 | 0.087188 |
500 | 0.1 | 0.030000 | 0.000000 | 0.030000 | 0.023976 |
 ](https://blog.dramancompany.com/wp-content/uploads/2016/11/image2016-11-8-15-45-29.png)[
](https://blog.dramancompany.com/wp-content/uploads/2016/11/image2016-11-8-15-45-29.png)[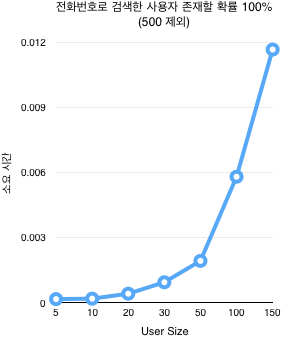
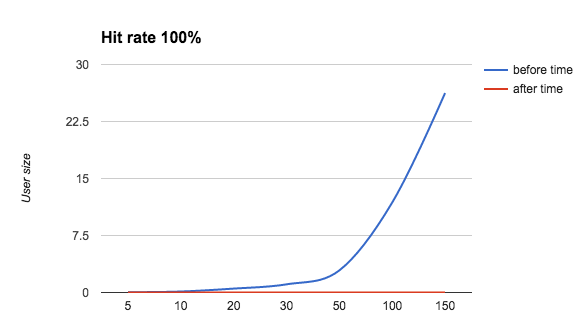
성능 비교
| User size | Hit rate | before time | after time | 비교(%) |
| 5 | 1 | 0.034104 | 0.000177 | 0.5190007037 |
| 5 | 0.5 | 0.018707 | 0.000147 | 0.7858021062 |
| 5 | 0.1 | 0.000003 | 0.000003 | 100 |
| 10 | 1 | 0.129068 | 0.000197 | 0.1526327207 |
| 10 | 0.5 | 0.094217 | 0.000228 | 0.2419945445 |
| 10 | 0.1 | 0.021157 | 0.00017 | 0.8035165666 |
| 20 | 1 | 0.51311 | 0.000426 | 0.08302313344 |
| 20 | 0.5 | 0.356309 | 0.000432 | 0.1212430783 |
| 20 | 0.1 | 0.086764 | 0.000316 | 0.3642063529 |
| 30 | 1 | 1.072212 | 0.000952 | 0.08878841125 |
| 30 | 0.5 | 0.807687 | 0.000856 | 0.1059816488 |
| 30 | 0.1 | 0.199311 | 0.000484 | 0.242836572 |
| 50 | 1 | 2.907888 | 0.001935 | 0.06654314059 |
| 50 | 0.5 | 2.136653 | 0.00127 | 0.05943875772 |
| 50 | 0.1 | 0.546068 | 0.000728 | 0.1333167298 |
| 100 | 1 | 11.838261 | 0.005805 | 0.04903591837 |
| 100 | 0.5 | 8.62645 | 0.004177 | 0.04842084519 |
| 100 | 0.1 | 2.157522 | 0.001609 | 0.07457629633 |
| 150 | 1 | 26.241357 | 0.011655 | 0.04441462383 |
| 150 | 0.5 | 19.406512 | 0.00836 | 0.0430783234 |
| 150 | 0.1 | 4.908961 | 0.002741 | 0.05583666279 |
| 500 | 1 | 294.109574 | 0.121817 | 0.04141891688 |
| 500 | 0.5 | 222.306764 | 0.087188 | 0.03921967934 |
| 500 | 0.1 | 56.555782 | 0.023976 | 0.04239354342 |
표만봐도 알 수 있듯, 엄청난 효과를 가지고 시간이 단축되었음을 알 수 있다.
끝내며
Ruby 코드에서 가장 많이 사용하는 성능 최적화 툴들과, 성능 최적화 단계들 그리고 실제 예시에 대하여 살펴보았습니다. ruby-prof는 여기에 적은 것보다 훨씬 더 다양한 기능들(다양한 값의 측정, Rails 지원, Multi-thread 지원 등)을 제공하고 있습니다. 필요한 상황에 맞춰서 더 용이하게 사용하실 수 있습니다. 또한 위 tool들외에도 드라마앤컴퍼니에서는 AWS cloudwatch, New Relic, ELK 등 다양한 tool을 이용하여 실시간+사후 성능 모니터링을 진행하고 있습니다. 다음 글에서는 이번 글의 예시보다 조금 더 복잡했던 Paperclip + AWS S3의 성능 튜닝에 대해서 다뤄보겠습니다 :D